7장, 가치 있는 단위 테스트를 위한 리팩터링
2022.03.28
7.1 리팩터링할 코드 식별하기
7.1.1 코드의 네 가지 유형으로
모든 제품 코드는 2차원으로 분류할 수 있다.
- 복잡도 또는 도메인 유의성
- 협력자 수
코드 복잡도(code complexity)는 코드 내의 의사 결정(분기) 지점 수로 정의한다. 분기가 많을수록 복잡도도 높아진다.
도메인 유의성(domain significance) : 코드가 프로젝트의 문제 도메인에 얼마나 의미 있는지를 나타낸다.
도메인 계층의 모든 코드는 최종 사용자의 목표와 직접적인 연관성이 있으므로 도메인 유의성이 높다.
복잡한 코드와 도메인 유의성을 갖는 코드가 단위 테스트에서 가장 이롭다.
해당 테스트는 회귀 방지에 뛰어나기 때문이다. 도메인 코드는 복잡할 필요가 없으며, 복잡한 코드는 도메인 유의성이 나타나지 않아도 테스트할 만하다.
협력자의 유형도 중요하다. 도메인 모델이라면 프로세스 외부 협력자를 사용하면 안 된다.
목 체계가 복잡하여 유지비가 더 들기 때문이다. 또한, 리팩터링 내성을 잘 지키려면 애플리케이션 경계를 넘는 상호 작용을 검증하는 데만 사용해야 한다.
도메인 모델 및 알고리즘을 단위 테스트하면 노력 대비 가장 이롭다. 이러한 단위 테스트는 매우 가치 있고 저렴하다.
해당 코드가 복잡하거나 중요한 로직을 수행해서 테스트의 회귀 방지가 향상되기 때문에 가치 있다.
또한, 코드에 협력자가 없어서 테스트 유지비를 낮추기 때문에 저렴하다.
코드 복잡도, 도메인 유의성 협력자 수의 조합으로 네 가지 코드 유형을 볼 수 있다.
- 도메인 모델과 알고리즘
- 간단한 코드
- 컨트롤러
- 지나치게 복잡한 코드
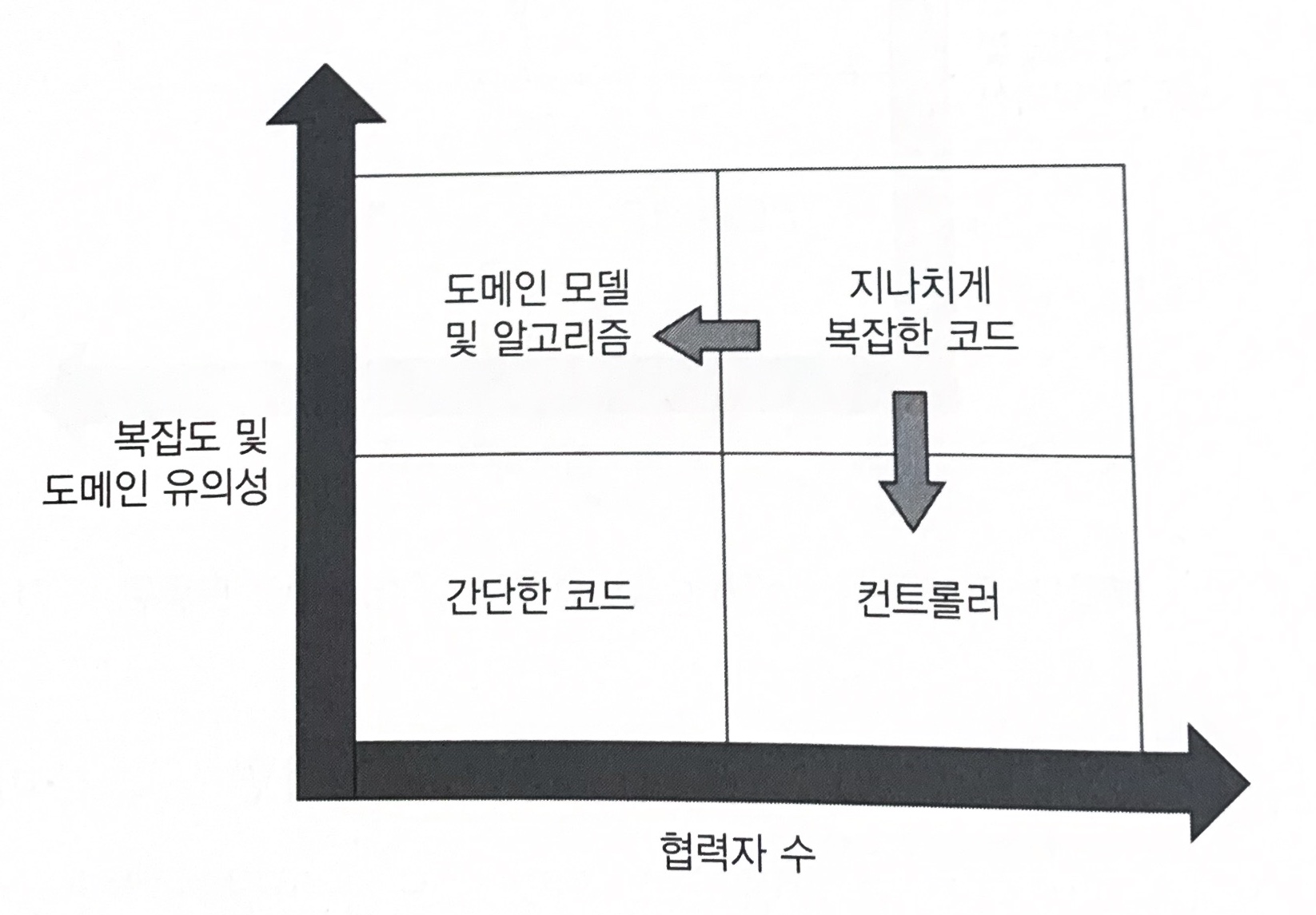
가장 문제가 되는 코드 유형은 지나치게 복잡한 코드다.
실제 구현이 까다로울수 있지만, 지나치게 복잡한 코드를 알고리즘과 컨트롤러라는 두 부분으로 나누는 것이 일반적이다.
코드가 더 중요해지거나 복잡해질수록 협력자는 더 적어야 한다.
좋지 않은 테스트를 작성하는 것보다는 테스트를 전혀 작성하지 않는 편이 낫다.
7.1.2 험블 객체 패턴을 사용해 지나치게 복잡한 코드 분할하기
지나치게 복잡한 코드를 쪼개려면, 험블 객체 패턴(Humeble Object)을 써야한다.
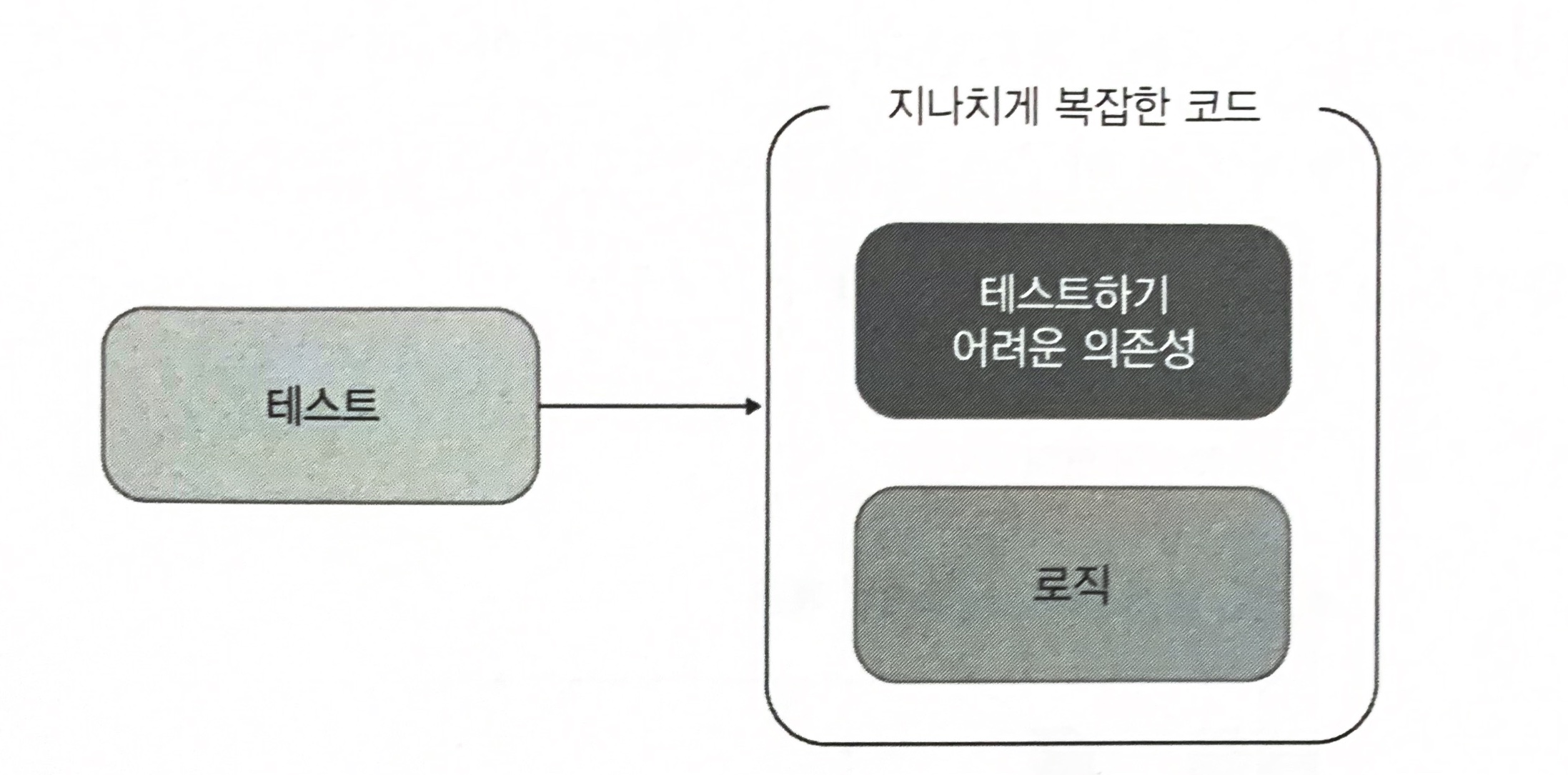
테스트 대상 코드의 로직을 테스트하려면, 테스트가 가능한 부분을 추출해야 한다. 결과적으로 코드는 테스트 가능한 부분을 둘러싼 얇은 험블 래퍼(humble wrapper)가 된다.
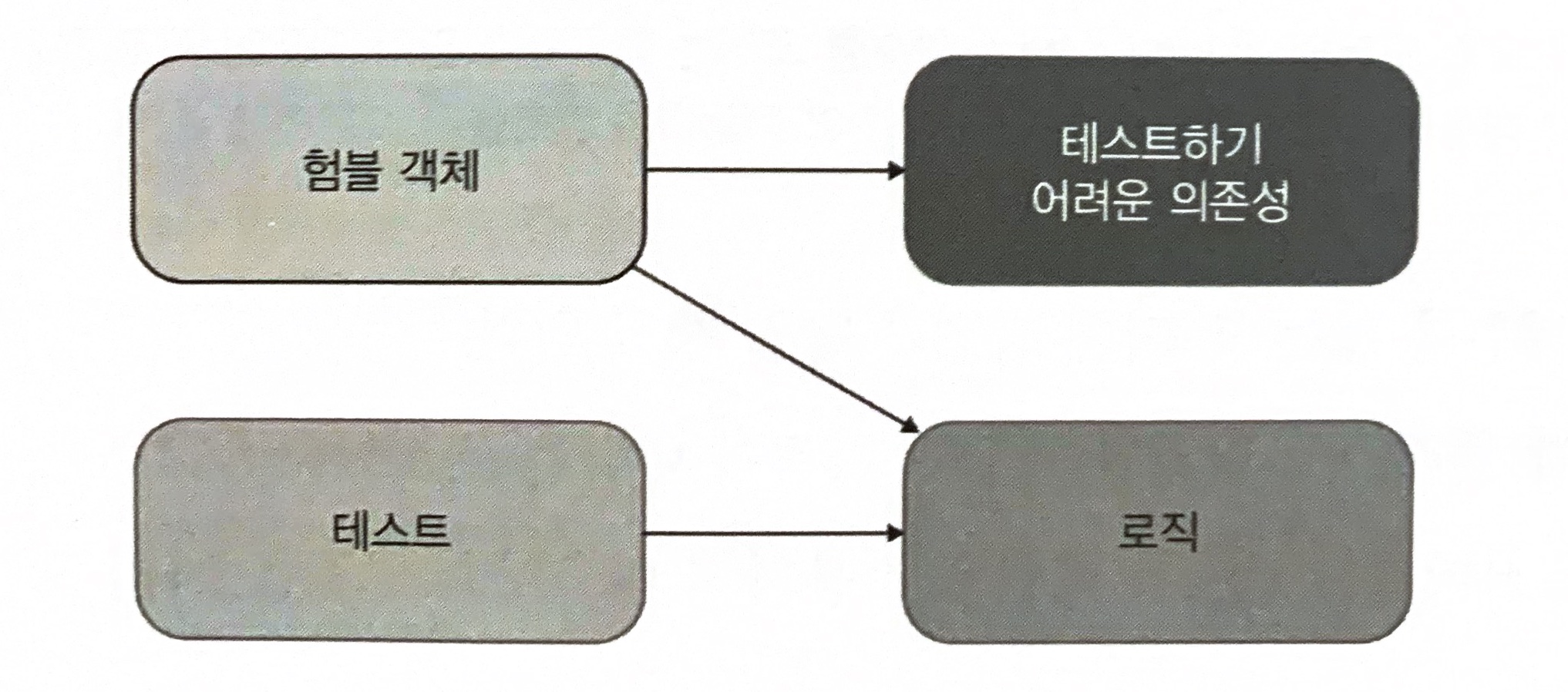
사실 육각형 아키텍처와 함수형 아키텍처 모두 정확히 이 패턴을 구현한다.
육각형 아키텍처는 비지니스 로직과 프로세스 외부 의존성과의 통신을 분리한다. 이는 도메인 계층과 애플리케이션 서비스 계층이 각각 담당하는 것이다.
함수형 아키텍처는 더 나아가 프로세스 외부 의존성뿐만 아니라 모든 협력자와의 커뮤니케이션에서 비지니스 로직을 분리한다.
즉, 함수형 코어에는 아무런 협력자도 없다. 함수형 코어의 모든 의존성은 불변이다.
험블 객체 패턴을 보는 또 다른 방법은 단일 책임 원칙을 지키는 것이다. 이는 각 클래스가 단일한 책임만 가져야 한다는 원칙이다. 그러한 책임 중 하나로 늘 비지니스 로직이 있는데, 이 패턴을 적용하면 비지니스 로직을 거의 모든 것과 분리할 수 있다.
테스트 가능한 설계가 어떻게 테스트를 용이하게 할 뿐만 아니라 유지 보수도 쉽게 해주는지에 대해 생각하면 흥미로운 부분이다.
7.2 가치 있는 단위 테스트를 위한 리팩터링하기
7.2.1 고객 관리 시스템 소개
아래 세 가지 비지니스 규칙이 있다.
- 사용자 이메일이 회사 도메인에 속한 경우 해당 사용자는 직원으로 표시된다. 그렇기 않으면 고객으로 간주한다.
- 시스템은 회사의 직원 수를 추적해야 한다. 사용자 유형이 직원에서 고객으로, 또는 그 반대로 변경되면 이 숫자도 변경해야 한다.
- 이메일이 변경되면 시스템은 메시지 버스로 메시지를 보내 외ㅚ부 시스템에 알려야 한다.
User 클래스에는 네 개의 의존성이 있으며, 그중 두개는 명시적이고 나머지 두개는 암시적이다. 명시적 의존성은 userId와 newEmail 인수다. 이 둘은 값이므로 클래스의 협력자 수에는 포함되지 않는다. 암시적인 것은 Database와 MessageBus이다. 이 둘은 프로세스 외부 협력자다. 도메인 유의성이 높은 코드에서 프로세스 외부 협력자는 사용하면 안 된다.
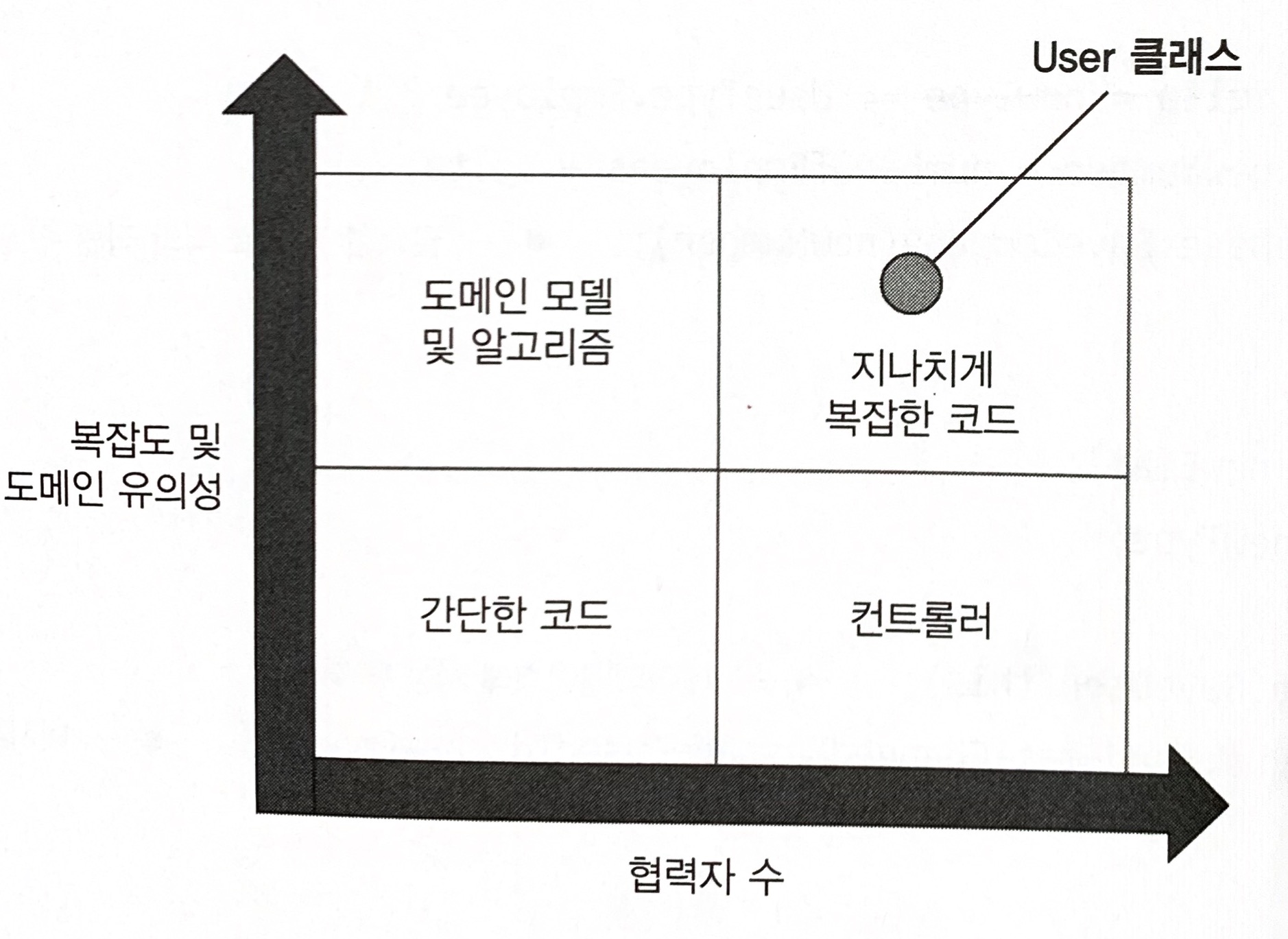
도메인 클래스가 스스로 데이터베이스를 검색하고, 다시 지정하는 이러한 방식을 활성 레코드 패턴(Active Record)이라고 한다. 단순 프로젝트나 단기 프로젝트에서는 잘 작동하지만 코드베이스가 커지면 확장하지 못하는 경우가 많다. 그 이유는 정확히 두 가지 책임, 즉 비지니스 로직과 프로세스 외부 의존성과의 통신 사이에 분리가 없기 때문이다.
7.2.2 1단계: 암시적 의존성을 명시적으로 만들기
테스트 용이성을 개선하는 일반적인 방법은 암시적 의존성을 명시적으로 만드는 것이다.
도메인 모델은 직접적으로든 간접적으로든(인터페이스를 통해)) 프로세스 외부 협력자에게 의존하지 않는 것이 훨씬 더 깔끔하다. 이것이 바로 육각형 아키텍처에서 바라는 바다. 도메인 모델은 외부 시스템과의 통신을 책임지지 않아야 한다.
7.2.3 2단계: 애플리케이션 서비스 계층 도입
도메인 모델이 외부 시스템과 직접 통신하는 문제를 극복하려면 다른 클래스인 험블 컨트롤러(humble controller, 육각형 아키텍처 분류상 애플리케이션 서비스)로 책임을 옮겨야 한다. 일반적으로 도메인 클래스는 다른 도메인 클래스나 단순 값과 같은 프로세스 내부 의존성에만 의존해야 한다.
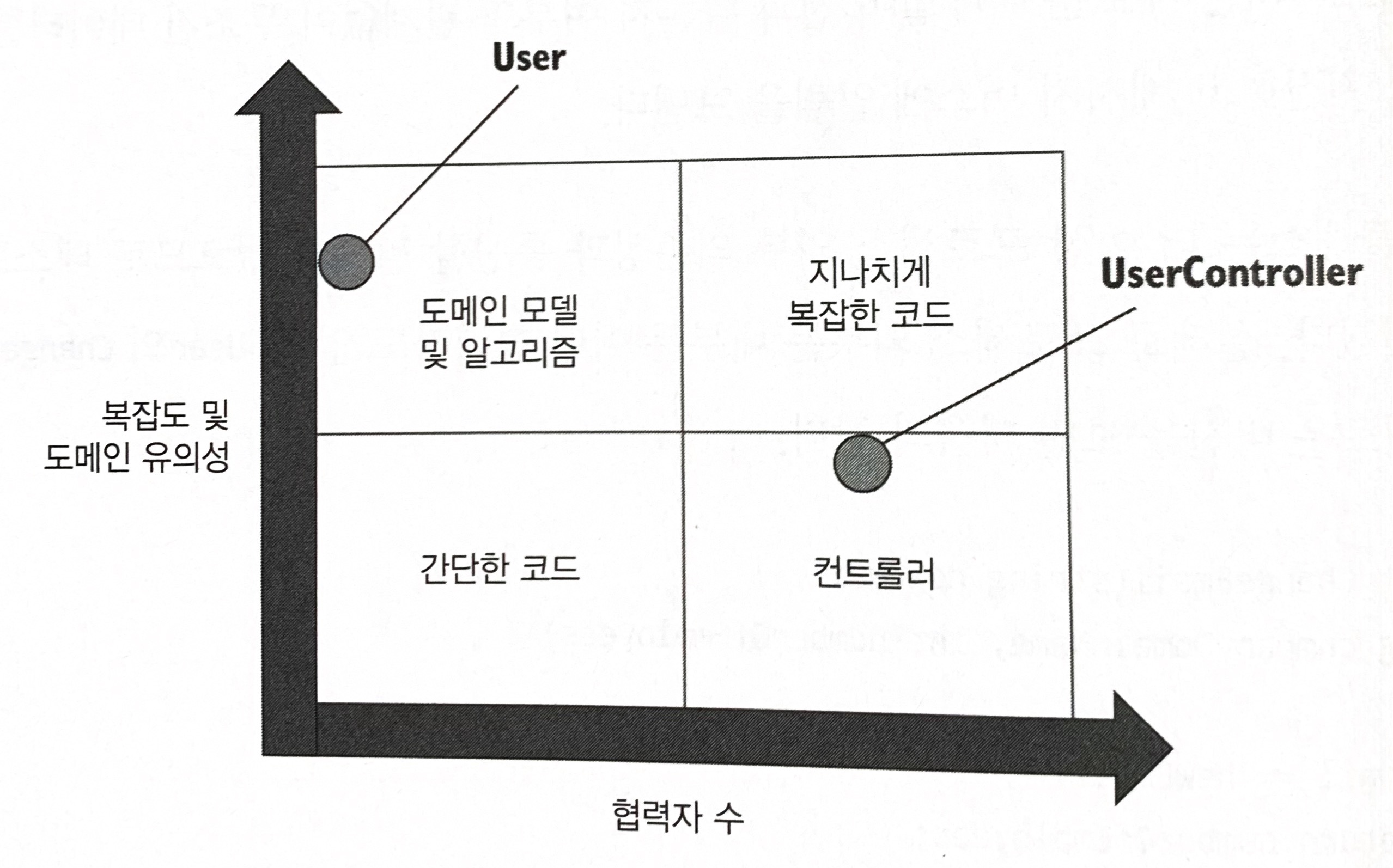
7.2.4 3단계: 애플리케이션 서비스 복잡도 낮추기
UserController가 컨트롤러 사분면에 확실히 있으려면 재구성 로직을 추출해야 한다.
ORM을 사용해 데이터베이스를 도메인 모델에 매핑하면, 재구성 로직을 옮기기에 적절한 위치가 될 수 있다.
ORM을 사용하지 않거나 사용할 수 없으면, 도메인 모델에 원시 데이터베이스 데이터로 도메인 클래스를 인스턴스화하는 팩토리 클래스를 작성하라.
이 팩토리 클래스는 별도 클래스가 될 수도 있고, 더 간단한 경우 기존 도메인 클래스의 정적 메서드가 도리 수도 있다.
7.2.5 4단계: 새 Company 클래스 소개
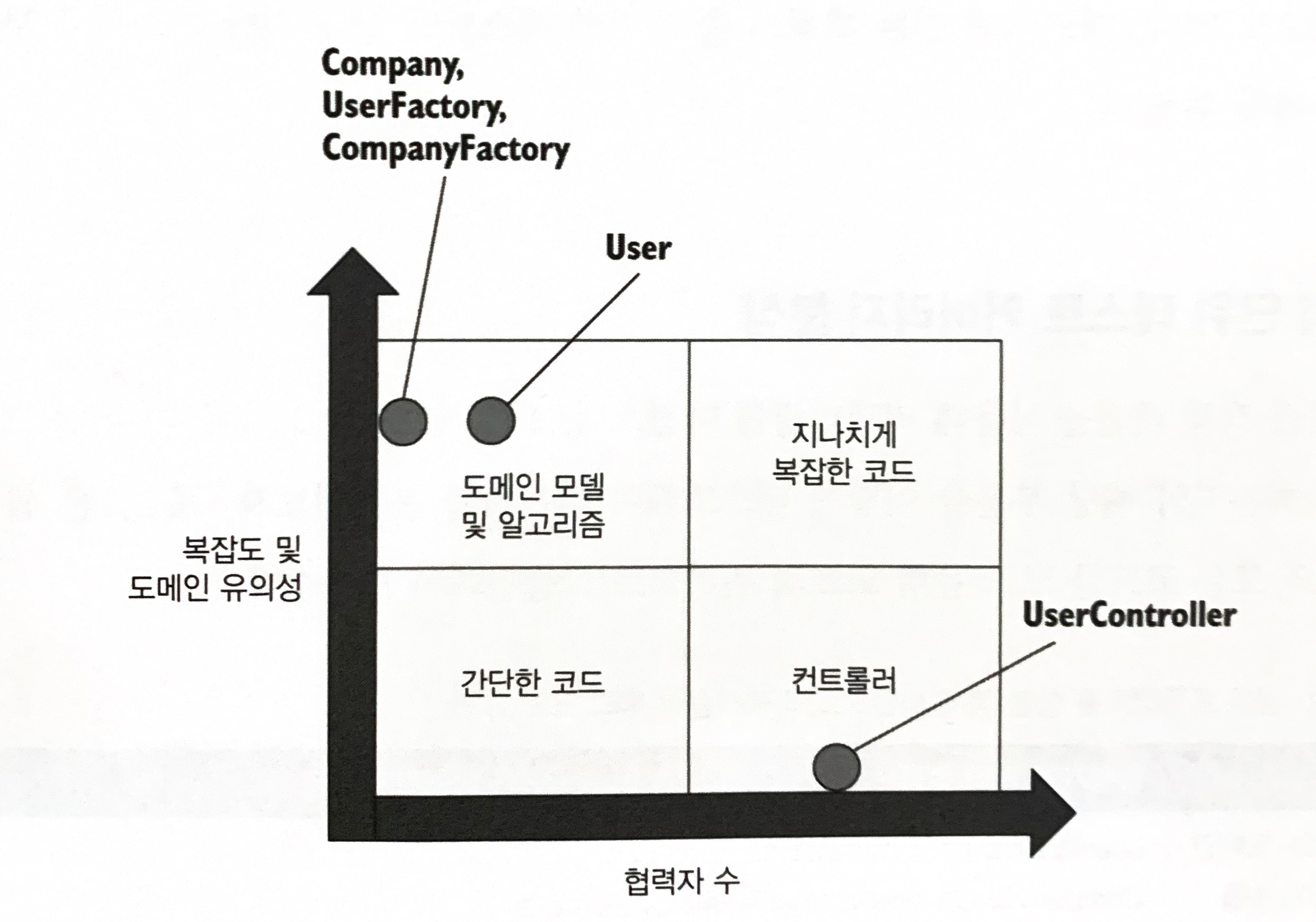
모든 복잡도가 팩토리로 이동했기 때문에 UserController는 확실히 컨트롤러 사분면에 속한다. 이 클래스가 담당하는 것은 모든 협력자를 한데 모으는 것이다.
함수형 아키텍처와 비슷한 점을 생각해보면, 함수형 코어와 위의 도메인 계층도 프로세스 외부 의존성과 통신하지 않는다.
두 가지 구현의 차이는 부작용 처리에 있다. 함수형 코어는 어떠한 부작용도 일으키지 않는다. 위의 도메인 모델은 부작용을 일으키지만, 이러한 모든 부작용은 변경된 사용자 이메일과 직원 수의 형태로 도메인 모델 내부에 남아있다. 컨트롤러가 User 객체와 Company 객체를 데이터베이스에 저장할 때만 부작용이 도메인 모델의 경계를 넘는다.
7.3 최적의 단위 테스트 컵저리지 분석
| 협력자가 거의 없음 | 협력자가 많음 | |
|---|---|---|
| 복잡도와 도메인 유의성이 높음 | User의 ChangeEmail(new Email, company), Company의 ChageNumberOfEmployess(delta) | ---- |
| 복잡도와 도메인 유의성이 낮음 | User와 Company의 생성자 | UserController의 ChangeEmail(userId, newMalil |
7.3.1 도메인 계층과 유틸리티 코드 테스트하기
좌측 상단 테스트 메서드는 비용 편익 측면에서 최상의 결과를 가져다준다. 코드의 복잡도나 도메인 유의성이 높으면 회귀 방지가 뛰어나고 협력자가 거의 없어 유지비도 가장 낮다.
7.3.2 나머지 세 사분면에 대한 코드 테스트하기
복잡도 낮고 협력자가 거의 없는 코드는 다음과 같이 User와 Company의 생서자를 들 수 있다.
public User(int userId, string email, UserType type)
{
UserId = userId;
Email = email;
Type = type;
}이러한 생성자는 단순해서 노력을 들일 필요가 없으며, 테스트는 회귀 방지가 떨어질 것이다.
복잡도가 높고 협력자가 많은 코드를 리팩터링으로 제거했으므로 테스트할 것이 없다.
7.3.3 전제 조건을 테스트해야 하는가?
public void ChageNumberOfEmployess(int delta)
{
Precondition.Requires(NumberOfEmployees + delta >= 0);
NumberOfEmployees += delta;
}위의 메서드는 음수가 돼서는 안 된다는 전제 조건이 있다. 이 전제 조건은 예외 상황에서만 활성화되는 보호 장치다.
위와 같은 전제 조건에 대한 테스트가 테스트 스위트에 있을 만큼 충분한 가치가 있는가?
여기에 어려운 규칙은 없지만, 일반적으로 권장하는 지침은 도메인 유의성이 있는 모든 전제 조건을 테스트하라는 것이다.
반면에, 도메인 유의성이 없는 전 제 조건을 테스트하는 데 시간을 들일 필요는 없다.
7.4 컨트롤러에서 조건부 로직 처리
조건부 로직을 처리하면서 동시에 프로세스 외부 협력자 없이 도메인 계층을 유지 보수하는 것은 까다롭고 절충이 있기 마련이다.
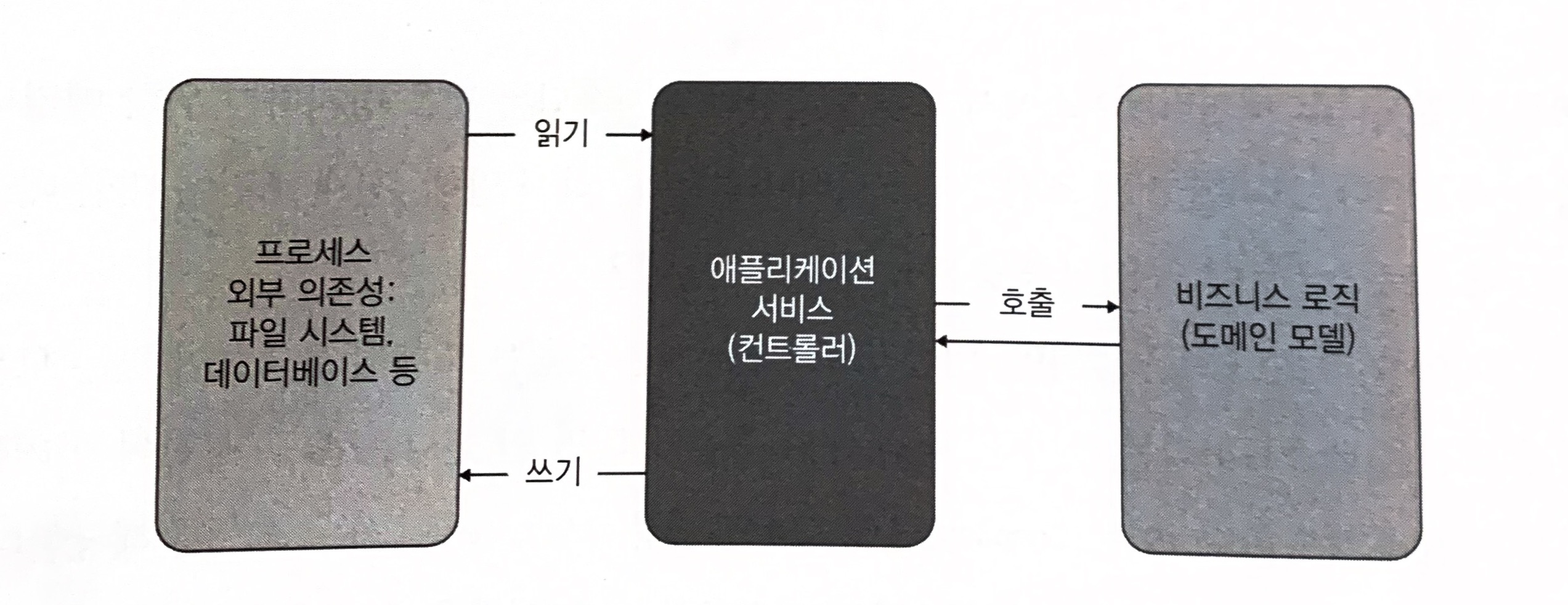
육각형 아케턱처와 함수형 아키텍처는 프로세스 외부 의존성에 대한 모든 참조가 비지니스 연산의 가장자리로 밀려났을 때 가장 효과적이다.
문제는 다음 세 가지 특성의 균형을 맞추는 것이다.
- 도메인 모델 테스트 유의성 : 도메인 클래스의 협력자 수와 유형에 따른 함수
- 컨트롤러 단순성 : 의사 결정(분기) 지점이 있는지에 따라 따름
- 성능 : 프로세스 외부 의존성에 대한 호출 수로 정의
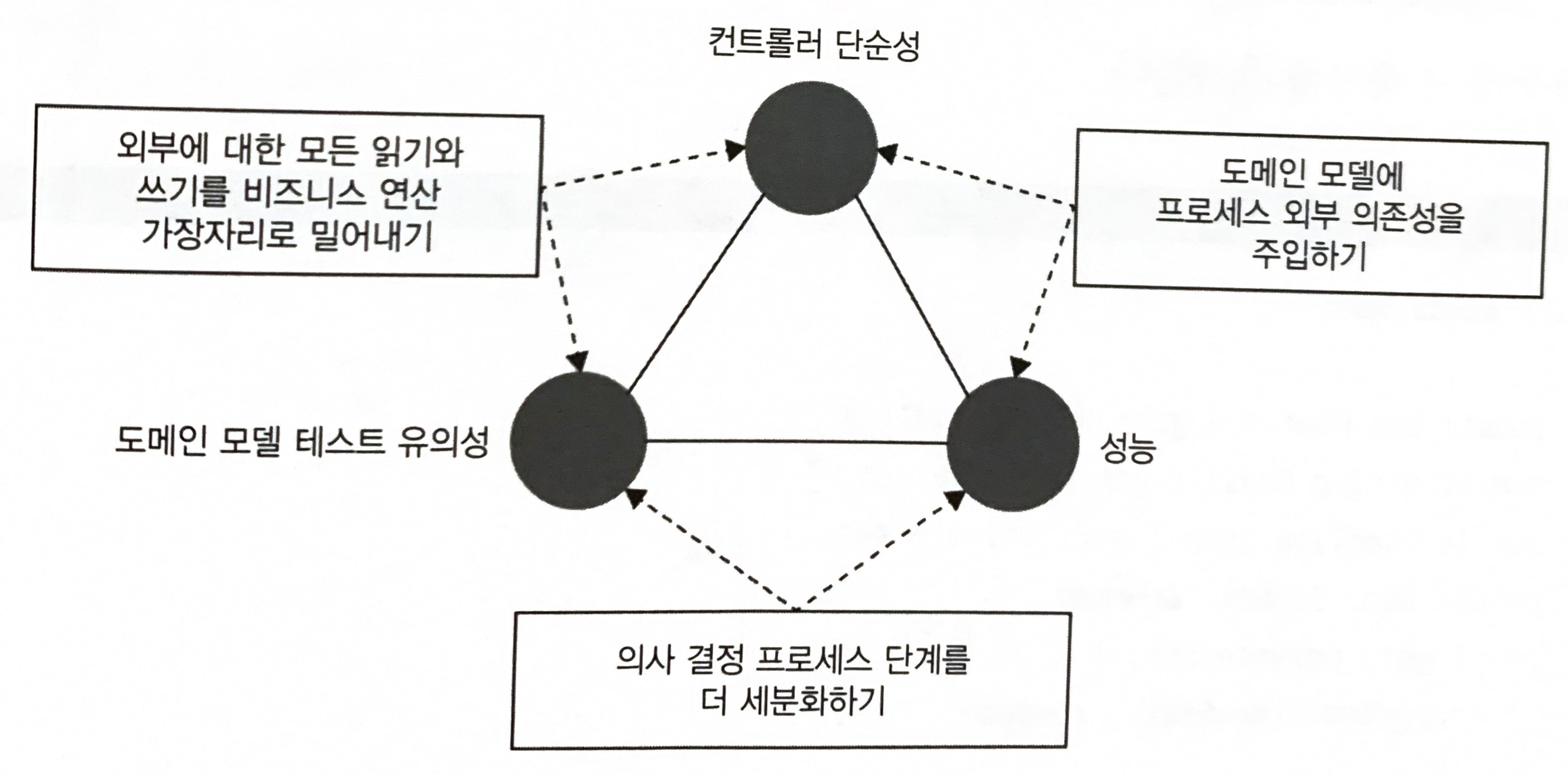
위의 세 가지 특성을 모두 충족하는 해법은 없다. 따라서 세 가지 중 두 가지를 선택해야 한다.
대부분의 소프트웨어 프로젝트에서는 성능이 매우 중요하므로 첫 번째 방법(외부에 대한 읽기와 쓰기를 비지니스 연산 가장자리로 밀어내기)은 고려할 필요가 없다.
두번째 옵션(도메인 모델에 프로세스 외부 의존성 주입하기)은 대부분 코드를 지나치게 복잡한 사분면에 넣는다. 이러한 코드는 테스트와 유지 보수가 훨씬 어려워지므로 이러한 방법은 피하는 것이 좋다.
세 번쨰 옵션(의사 결정 프로세스 단계를 더 세분화하기)는 컨트롤러를 더 복잡하게 만들지만, 이를 완화 할 수 있는 방법이 있다.
7.4.1 CanExecute/Execute 패턴 사용
컨트롤러 복잡도가 커지는 것을 원화하는 첫 번째 방법은 CanExecute/Execute 패턴을 사용해 비지니스 로직이 도메인 모델에서 컨트롤러로 유출되는 것을 방지하는 것이다.
이메일은 사용자가 확인할 때까지만 변경할 수 있다고 하자.
public string CanChangeEmail()
{
if(IsEmailConfirmed)
return "Can't change a confirmed email";
return null;
}
public void ChangeEmail(string newEmail, Company company)
{
Precondition.Requires(CanChangeEmail() == null);
// 메서드의 나머지 부분
}위 방법에는 두 가지 중요한 이점이 있다.
- 컨트롤러는 더 이상 이메일 변경 프로세스를 알 필요가 없다.
CanChangeEmail메서드를 호출해 연산을 수행할 수 있는지 확인하기만 하면 된다. 이 메서드에 여러 가지 유효성 검사가 있을 수 있고, 유효성 검사 모두 컨트롤러로부터 캡슐화돼 있다. ChangeEmail의 전제 조건이 추가돼도 먼저 확인하지 않으면 이메일을 변경할 수 없도록 보장한다.
따라서 컨트롤러에 CanChangeEmail을 호출하는 if 문이 있어도 if 문을 테스트할 필요는 없다. User 클래스의 전제조건을 단위 테스트하는 것으로 충분하다.
7.4.2 도메인 이벤트를 사용해 도메인 모델 변경 사항 추적
도메인 모델을 현재 상태로 만든 단계를 빼기 어려울 때가 있다. 그러나 애플리케이션에서 정확히 무슨 일이 일어나는지 외부 시스템에 알려야 하기 때문에 이러한 단계들을 아는 것이 중요할지도 모른다. 컨트롤러에 이러한 책임도 있으면 더 복잡해진다. 이를 피하려면, 도메인 모델에서 중요한 변경 사항을 추적하고 비지니스 연산이 완료된 후 해당 변경 사항을 프로세스 외부 의존성 호출로 변환한다. 도메인 이벤트(domain event)로 이러한 추적을 구현 할 수 있다.
도메인 이벤트는 애플리케이션 내에서 도메인 전문가에게 중요한 이벤트를 말한다.
도메인 전문가에게는 무엇으로 도메인 이벤트와 일반 이벤트(예: 버튼 클릭)를 구별하는지가 중요하다.
도메인 이벤트는 종종 시스템에서서 발생하는 중요한 변경 사항을 외부 애플리케이션에 알리는 데 사용된다.
도메인 이벤트는 컨트롤러에서 의사 결정 책임을 제거하고 해당 책임을 도메인 모델에 적용함으로써 외부 시스템과의 통신에 대한 단위 테스트를 간결하게 한다.
컨트롤러를 검증하고 프로세스 외부 의존성을 목으로 대체하는 대신, 단위 테스트에서 직접 도메인 이벤트 생성을 테스트할 수 있다.
물론, 오케스트레이션이 올바르게 수행되는지 확인하고자 컨트롤러를 테스트해야 하지만, 그렇게 하려면 훨씬 더 작은 테스트가 필요하다.
7.5 결론
이번에 다뤘던 주제는 외부 시스템에 대한 애플리케이션의 부작용을 추상화하는 것이었다. 비지니스 연산이 끝날 때까지 이러한 부작용을 메모리에 둬서 추상화하고, 프로세스 외부 의존성 없이 단순한 단위 테스트로 테스트할 수 있다. 도메인 이벤트는 메시지 버스에서 메시지에 기반한 추상화에 해당한다.
추상화할 것을 테스트하기보다 추상화를 테스트하는 것이 더 쉽다.
잠재적인 파편화가 있더라도 비지니스 로직을 오케스트레이션에서 분리하는 것은 많은 가치가 있다.
분리하면 단위 테스트 프로세스가 크게 간소화되기 때문이다.
식별할 수 있는 동작과 수현 세부 사항을 양파의 여러 겹으로 생각하라. 외부 계층의 관점에서 각 계층을 테스트하고, 해당 계층이 기저 계층과 어떻게 통신하는지는 무시하라. 이러한 계층을 하나씩 벗겨가면서 관점을 바꾸게 된다. 이전에 구현 세부 사항이었던 것이 이제는 식별할 수 있는 동작이 되며, 이는 또 다른 테스트로 다루게 된다.
요약
- 코드 복잡도는 코드에서 의사 결정 지점 수에 따라 명시적으로(코드) 그리고 암시적으로(코드가 사용하는 라이브러리) 정의된다.
- 도메인 유의성은 프로젝트의 문제 도메인에 대해 코드가 얼마나 중요한지를 보여준다.
- 복잡한 코드와 도메인 유의성을 갖는 코드는 해당 테스트의 회귀 방지가 뛰어나기 때문에 단위 테스트에서 가장 이롭다.
- 모든 제품 코드는 복잡도 또는 도메인 유의성과 협력자 수에 따라 네 가지 유형의 코드로 분류할 수 있다.
- 도메인 모델 및 알고리즘은 단위 테스트에 대한 노력대비 가장 이롭다.
- 간단한 코드(복잡도와 도메인 유의성이 낮음. 협력자가 거의 없음)는 테스트할 가치가 전혀 없다.
- 컨트롤러(복잡도와 도메인 유의성이 낮음. 협력자가 많음)는 통합 테스트를 통해 간단히 테스트해야 한다.
- 지나치게 복잡한 코드는 컨트롤러와 복잡한 코드로 분할해야 한다.
- 도메인 유의성이 있으면 전제 조건을 테스트하고, 그 외의 경우에는 테스트하지 않는다.
- 비지니스 로직과 오케스트레이션을 분리할 때는 다음과 같이 세 가지 중요한 특성이 있다.
- 도메인 모델 테스트 유의성 : 도메인 클래스 내 협력자 수와 유형에 대한 함수
- 컨트롤러 단순성 : 컨트롤러에 의사 결정 지점이 있는지에 따라 다름
- 성능 : 프로세스 외부 의존성에 대한 호출 수로 정의
- 항상 세가지 특성 중 최대 두 가지를 가질 수 있다.
- 외부에 대한 모든 읽기와 쓰기를 비지니스 연산 가장자리로 밀어내기 : 컨트롤러를 단순하게 유지하고 도메인 모델 테스트 유의성을 지키지만, 성능이 저하된다.
- 도메인 모델에 프로세스 외부 의존성을 주입하기 : 성능을 유지하고 컨트롤러를 단순하게 하지만, 도메인 모델의 테스트 유의성이 떨어진다.
- 의사 결정 프로세스 단계를 더 세분화하기 : 성능과 도메인 모델 테스트 유의성을 지키지만, 컨트롤러의 단순함을 포기한다.
- 추상화할 것을 테스트하기보다는 추상화를 테스트하는 것이 더 쉽다.