9장, 기초
2022.07.06
아키텍처 스타일의 명칭은 숙련된 아키텍트들 사이에서 간명하게 지칭할 수 있는 이름으로 붙여 놓았습니다. 예를 들어, 한 아키텍트가 레이어드 모놀리스에 대해 이야기할 경우, 그의 목표는 구조적인 측면과 어떤 종류의 아키텍처 특성이 알맞는지 살펴보고 통상적인 배포 모델과 데이터 전략 등 다양한 정보를 이해하는 것이다. 따라서 아키텍트는 기초적인 아키텍처 스타일의 명칭에 익숙해져야 한다.
9.1 기초 패턴
소프트웨어 아키텍처의 역사를 통틀어 끊임없이 나타나고 또 나타나는 패턴이 있는데, 이런 패턴들은 코드, 배포, 또는 아키텍처의 다른 부분을 구성하는 시야를 넓혀준다. 예를 들어, 레이어는 기능에 따라 서로 다른 관심사를 분리하는 개념으로, 소프트웨어 자체만큼이나 오래됐습니다.
9.1.1 진흙 잡탕
진흙잡탕은 요즘에는 보통 실제 내부 구조라 할 만한 것은 하나도 없는, 데이터베이스를 직접 호출하는 이벤트 핸들러를 가진 단순한 스크립팅 애플리케이션을 가리킨다. 보통 이렇게 별 대수롭지 않게 시작한 애플리케이션이 나중에 점점 규모가 커지면서 처치 곤란한 상태가 된다.
구조가 없으면 앞으로 뭔가 변경하기가 점점 더 어려워지고, 배포, 테스트, 확장 성능 역시 고통스럽기 때문이다. 일부러 진흙잡탕을 만드는 아키텍트는 없겠지만, 많은 프로젝트가 코드 품질 및 구조에 관한 거버넌스가 결여된 탓에 본의 아니게 그렇게 된다.
9.1.2 유니터리 아키텍처
소프트웨어 태동기에는 단 1대의 컴퓨터에서 소프트웨거가 돌아갔다. 이후 하드웨어/소프트웨어는 다양한 진화 세대를 거치면서 처음에는 단일 엔티티로 시작했다가 보다 정교한 기능이 점점 더 많이 필요해지면서 나누었다.
이제 유니터리(unitary , 단일, 통일) 시스템은 임베디드 시스템과 그 밖에 매우 제약이 많은 극소수 환경을 제외하면 거의 쓰이지 않는다.
9.1.3 클라이언트/서버
시간이 갈수록 단일 시스템에서 여러 기능을 분리할 필요성이 대두되었고 그 분리 방법은 많은 아키텍처 스타일의 기초가 되었다. 실제로 대부분의 아키텍처 스타일은 시스템에 있는 여러 부분을 효과적으로 분리하는 방법을 다룬다.
프론트엔드와 백엔드로 기술적으로 기능을 분리한 2티어(two-tier) 또는 클라이언트/서버 아키텍처는 대표적인 기본 아키텍처 스타일이다.
데스크톱 + 데이터베이스 서버
이 아키텍처는 표준 네트워크 프로토콜을 통해 접속 가능한 스탠드얼론(standalone, 단독형, 독립형) 데이터베이스 서버와 잘 맞았다. 덕분에 프레젠테이션 로직은 데스크톱에 두고 (양과 복잡도 모두) 계산량이 많은 액션은 사양이 탄탄한 데이터베이스 서버에서 실행했다.
브라우저 + 웹 서버
현대 웹 개발 시대가 도래하면서 웹 브라우저가 웹 서버에 접속하는(그리고 웹 서버는 다시 데이터베이스 서버에 접속하는) 형태로 분리하는 것이 일반화됐습니다. 클라이언트는 데스크톱보다 훨씬 가벼운 브라우저로 대체되었고 내외부 방화벽 모두 더 넓은 범위로 배포가 가능해졌다.
3티어
1990년대 후반에 인기를 끈 3티어(three-tier) 아키텍처는 더 많은 레이어로 분리한다. 고 성능 데이터베이스 서버를 사용하는 데이터베이스 티어, 애플리케이션 서버가 관리하는 애플리케이션 티어, 프런트엔드 티어, 이렇게 세 티어가 완성됐다.
9.2 모놀리식 대 분산 아키텍처
아키텍처 스타일은 크게 (전체 코드를 단일 단위로 배포하는) 모놀리식과 (원격 액세스 프로토콜을 통해 여러 단위로 배포하는) 분산형, 두 종류이다.
분산 아키텍처 스타일은 모놀리식 아키텍처 스타일에 비해 성능, 확장성, 가용성 측면에서 훨씬 강력하지만, 이런 파워에도 결코 무시할 수 없는 트레이드오프가 수반된다. 모든 분산 아키텍처에서 처음 맞닥뜨리게 되는 이슈들은 the fallacies of distributed computing : 분산 컴퓨팅의 오류라는 글에서 최초 거론되었다.
여기서 오류(fallacy)는 옳다고 믿거나 가정하지만 실은 틀린 것을 말한다.
9.2.1 오류 #1 네트워크는 믿을 수 있다
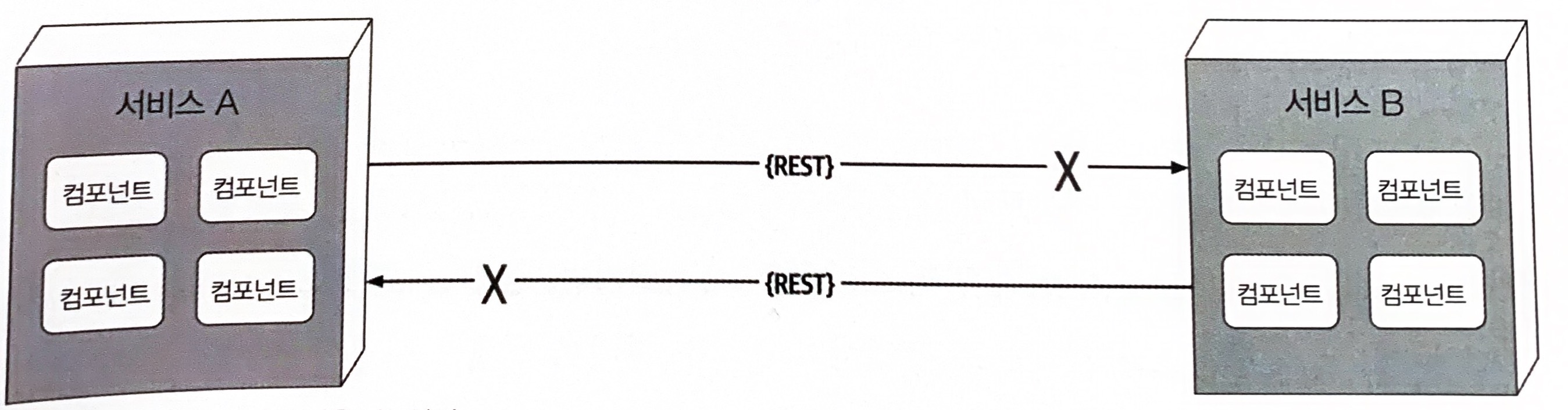
개발자, 아키텍트 모두 네트워크는 믿을 수 있다고 전제하지만 실제로 전혀 그렇지 않다. 네트워크의 신뢰도는 점점 좋아지고 있긴 하나 아직도 미덥지 못한 게 사실이다. 분산 아키텍처는 그 특성상 서비스를 오가는, 또 서비스 간에 이동하는 네트워크에 의존하므로 이것은 아주 중요한 문제이다.
시스템이 네트워크에 더 의존할수록 시스템의 신뢰도는 잠재적으로 떨어질 가능성이 있다.
9.2.2 오류 #2 레이턴시는 0이다
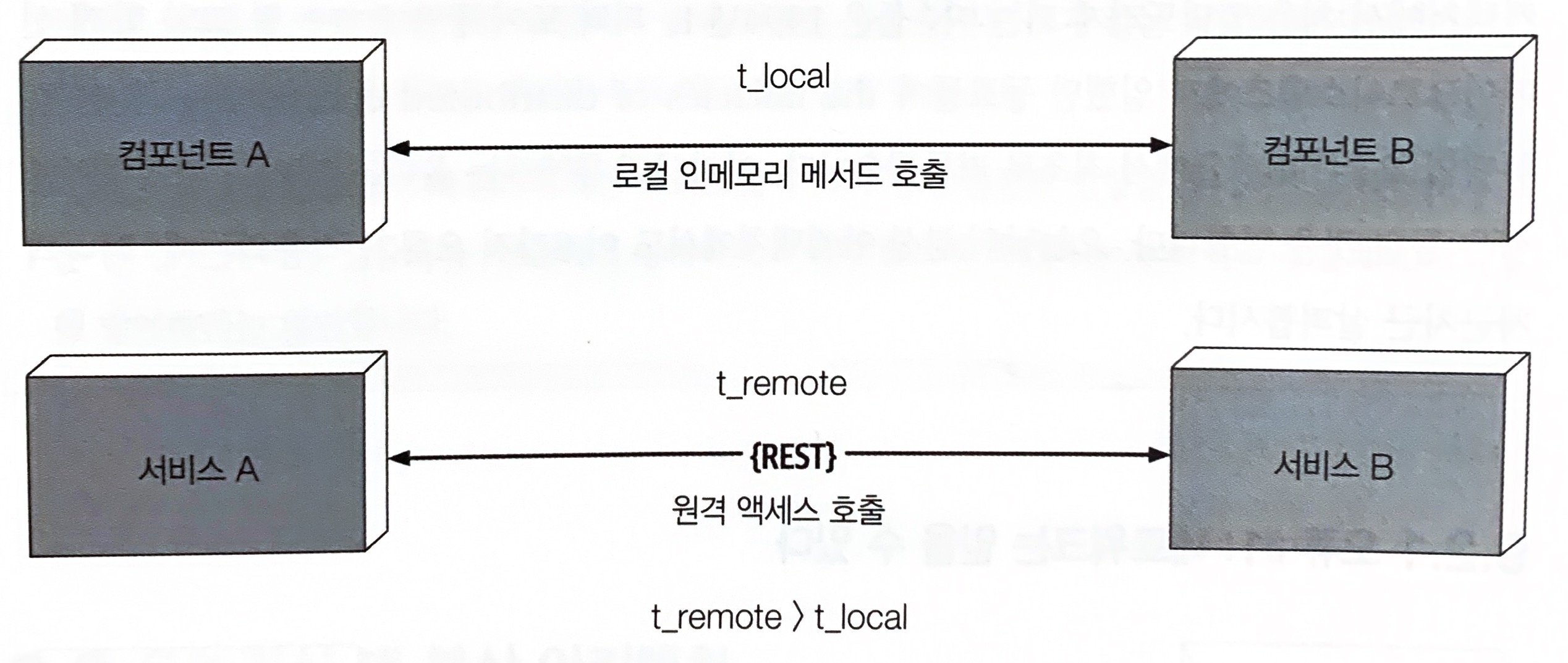
메서드나 함수를 이용해 다른 컴포넌트를 로컬 호출하면 그 소요 시간은 대게 나노 초 내지 밀리초 단위로 측정되지만, 동일한 호출을 원격 엑세스 프로토콜을 통해서 수행하면 서비스 엑세스 시간이 밀리초 단위로 측정된다.
따라서 t_remote는 항상 t_local보다 클 수밖에 없고 모든 분산 아키텍처에서 레이턴시는 0이 아니다.
아키텍트는 어떤 분산 아키텍처를 구축하든지 간에 평균 레이턴시는 반드시 알아야 한다. 이 것이 분산 아키텍처가 실현 가능한지 판단하는 유일한 방법이다.
평균 레이턴시가 60밀리초에 불과해도 95번째 백분위수는 400밀리초 있 수 있다. 보통 이런 긴 꼬리(long tail) 레이턴시가 분산 아키텍처의 성능을 저해하는 주범이 된다.
9.2.3 오류 #3 대역폭은 무한하다
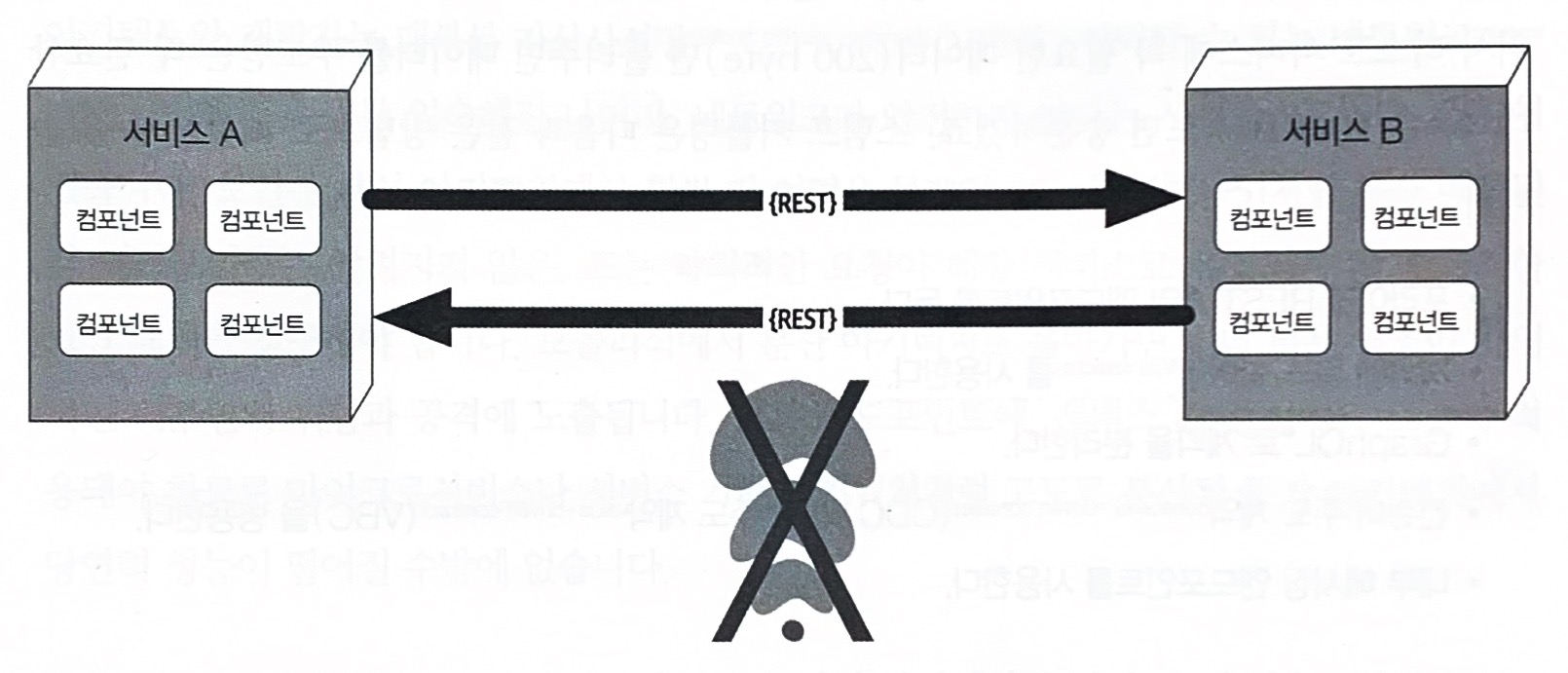
모놀리식 아키텍처는 비지니스 요청을 처리하는 데 그리 큰 대역폭이 필요하지 않으므로 대역폭이 문제될 일은 별로 없다. 하지만 마이크로서비스 분산 아키텍처에서 시스템이 자잘한 배포 단위(서비스)로 쪼개지면 이 서비스들 간에 주고받는 통신이 대역폭을 상당히 점유하여 네트워크가 느려지고, 결국 레이턴시와 신뢰성에도 영향을 미친다.
서비스 A에서 없는 데이터는 서비스 B를 호출해서 가져오게 되는데, 필요한 데이터 200 byte뿐만 아니라 불필요한 데이터까지 포함되어 500KB를 받는 것을 스탬프 커플링(stamp coupling)이라고 한다. 초당 요청이 2,000번정도 발생하면 요청당 500KB 데이터가 반횐되니 1회 서비스간 호출에 소모되는 대역폭은 무려 1GB나 된다.
스탬프 커플링은 분산 아키텍처에서 상당히 많은 대역폭을 차지한다. 아래와 같은 방법으로 해결할 수 있다.
- 프라이빗 REST API 엔드포인트를 둔다.
- 계약에 필드 셀렉터를 사용한다.
- GrahphQL로 계약을 분리한다.
- 컨슈머 주도 계약(consumer-driven constract, CDC)와 값 주도 계약(value-driven contract, VBC)을 병용한다.
- 내무 메시지 엔드포인트를 사용한다.
어떤 기법을 적용하든, 분산 아키텍처의 서비스 또는 시스템 간에 최소한의 데이터만 주고받도록 하는 것이 이 오류를 바로잡는 최선의 길이다.
9.2.4 오류 #4 네트워크는 안전하다
아키텍트와 개발자는 대부분 가상사설망(VPN), 신뢰할 수 있는 네트워크, 방화벽에 너무 익숙해진 나머지, 네트워크가 안전하지 않다는 사실을 망각하는 경향이 있다. 보안은 분산 아키텍처에서 훨씬 더 어려운 문제이다.
모든 엔드포인트에, 서비스 간 통신에도 보안이 적용돼야 하므로 마이크로서비스나 서비스 기반 아키텍처처럼 고도로 분산된 동기 아키텍처에서 당연히 성능이 떨어질 수밖에 없다.
9.2.5 오류 #5 토폴로지는 절대 안 바뀐다
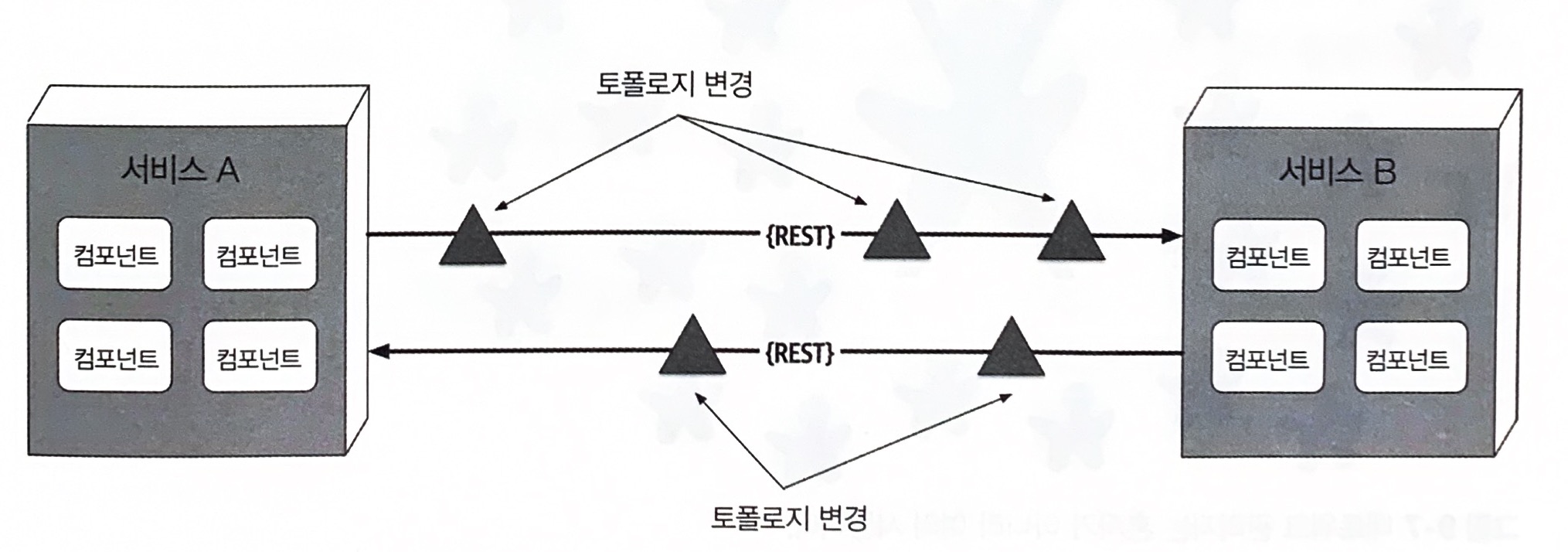
네트워크를 구성하는 모든 라우터, 허브, 스위치, 방화벽, 네트워크, 어플라이언스 등 전체 네트워크 토폴로지가 불변일 거란 가정은 섣부른 오해이다. 네트워크 토폴로지는 가만히 있질 않는다.
아키텍트는 운영자, 네트워크 관리자와 항상 소통을 하면서 무엇이, 언제 변경되는지 알고 있어야 한다.
9.2.6 오류 #6 관리자는 한 사람뿐이다
아키텍트는 언제나 한 사람의 관리자와만 협의하고 소통하면 된다는 오류에 빠지곤 한다. 대기업에서 일하는 네트워크 관리자는 보통 수십 명에 이른다. 분산 아키텍처는 복잡할 수밖에 없고 모든 것을 정상 궤도에 올려놓으려면 상당히 많은 조율 과정이 불가피하다.
9.2.7 오류 #7 운송비는 0이다
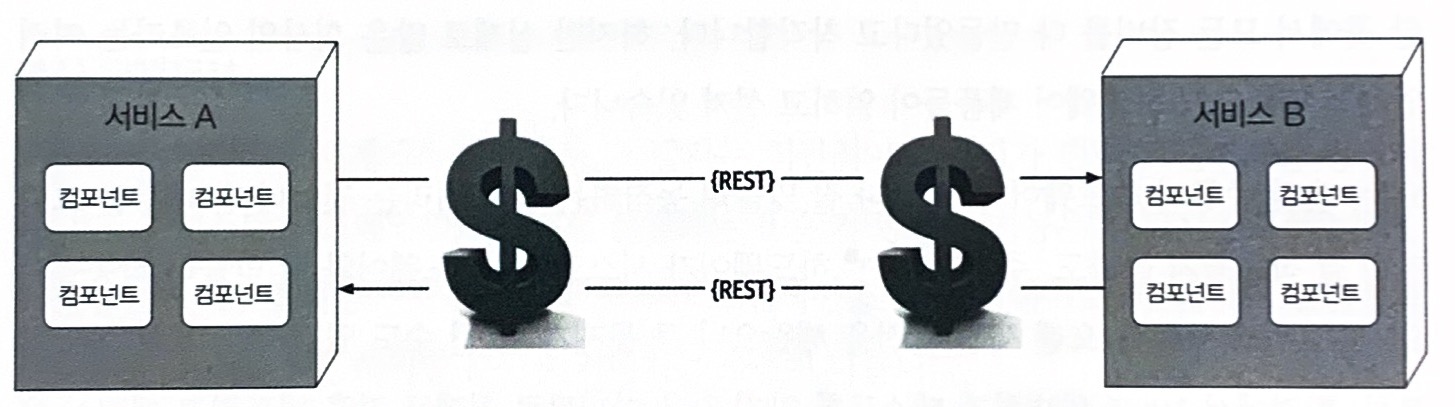
많은 소프트웨어에서 아키텍트들이 이 오류를 레이턴시와 혼동한다. 여기서 운송비는 레이턴시가 아니라 단순한 REST 호출을 하는데 소요되는 진짜 비용(actual cost)을 말한다.
분산 아키텍처는 하드웨어, 서버, 게이트웨이, 방화벽, 신규 서브넷, 프록시 등 리소스가 더 많이 동원되므로 모놀리식 아키텍처보다 비용이 훨씬 더 든다.
9.2.8 오류 #8 네트워크는 균일하다
아키텍트, 개발자는 대부분 네트워크가 균일하다, 즉 어느 네트워크 하드웨어 업체 한 곳에서 모든 장비를 다 만들었다고 착각한다. 하지만 실제로 많은 회사의 인프라는 여러 업체의 네트워크 하드웨어 제품들이 얽히고 설켜 있다.
네트워크 표준은 오랜 세월 발전해왔으니 큰 문제가 안 될 수도 있겠지만, 모든 상황과 부하, 환경에서 100% 완벽하게 테스트를 마친 것은 아니므로 실제 간혹 네트워크 패킷이 유실되는 사고도 심심찮게 일어난다.
9.2.19 오류 #9 다른 분산 아키텍처 고려 사항
분산 로깅
분산 아키텍처는 애플리케이션과 시스템 로그가 분산되어 있으므로 어떤 데이터가 누락된 근본 원인을 밝혀내기가 대단히 어렵고 시간도 많이 걸린다. 분산 아키텍처는 로그 종류만 해도 수백 가지에 달하고 위치도 제각각, 포맷도 제각각이라서 문제를 집어내기가 참 어렵다.
로깅 통합 도구를 사용하면 다양한 소스와 시스템에서 통합된 로그 및 콘솔로 데이터를 취합할 수 있지만 복잡하기 그지없는 분산 로그를 확인하기에는 역부족이다.
분산 트랜잭션
분산 아키텍처는 최종 일관성(eventual consistency)이라는 개념을 바탕으로 별도로 분리된 배포 단위에서 처리된 데이터를 미리 알 수 없는 어느 시점에 모두 일관된 상태로 동기화한다. 확장성, 성능, 가용성을 얻는 대가로 데이터 일관성과 무결성을 희생하는 트레이드오프인 셈이죠.
분산 트랜잭션을 관리하는 한 가지 방법으로 트랜잭셔널 사가(transactional saga)가 있다. 사가는 보상을 위해 이벤트를 소싱하거나 트랜잭션 상태를 관리하기 위해 유한 상태 기계를 활용한다. 사가 외에 BASE(basic, availability, soft state, eventual consistency) 트랜잭션도 사용한다. 소프트 상태(soft state)는 소스 -> 타깃으로의 데이터 전달과 데이터 소스 간 비일관성을 말한다.
시스템 또는 서비스의 기본 가용성에 따라 시스템은 아키텍처 패턴과 메시징을 사용하여 결국 언젠가 일관되게 맞춰질 것이ㅏㄷ.
계약 관리 및 버저닝
계약 생성, 유지보수, 버저닝 역시 분산 아키텍처에서 다소 까다롭다. 분산 아키텍처에서는 분리된 서비스와 시스템을 제각기 다른 팀과 부서가 소유하기 때문에 계약 유지보수가 특히 어렵다. 버전 구식화(deprecation)에 필요한 통신 모델은 더 더욱 복잡하다.